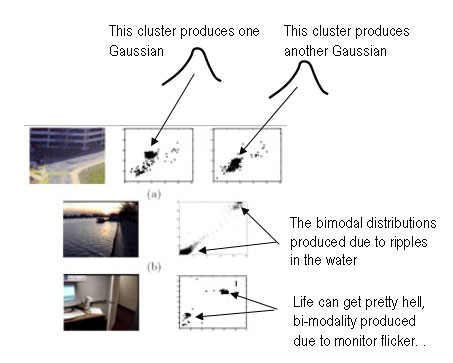
So now the question: given that we have these clusters of data sets, how do we come up with the Gaussian distributions? Normally, we would use the EM (Expectation maximization) algorithm to estimate the values of mu and sigma. A great tutorial/slides on EM can be found here.
EM achieves accuracy and "wraps" properly around the clusters after a number of iterations. In background modeling, each pixel is modeled as a mixture of gaussians. Hence, performing the EM on each pixel is a costly process, owing to the complexity of the EM algorithm. Stauffer et. al. suggests using an alternative approach as described in their paper "Adaptive background mixture models for real-time tracking". More on this, later.
No comments:
Post a Comment