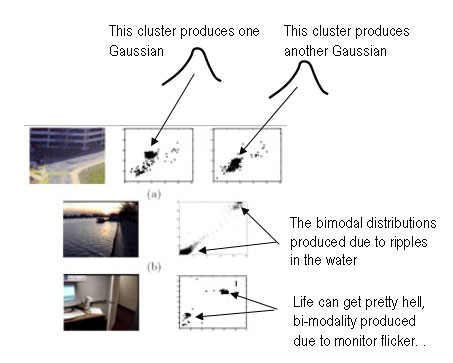
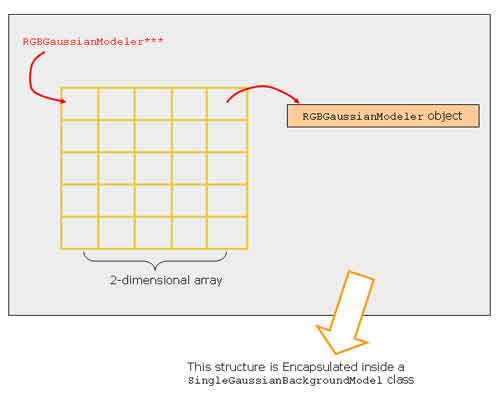
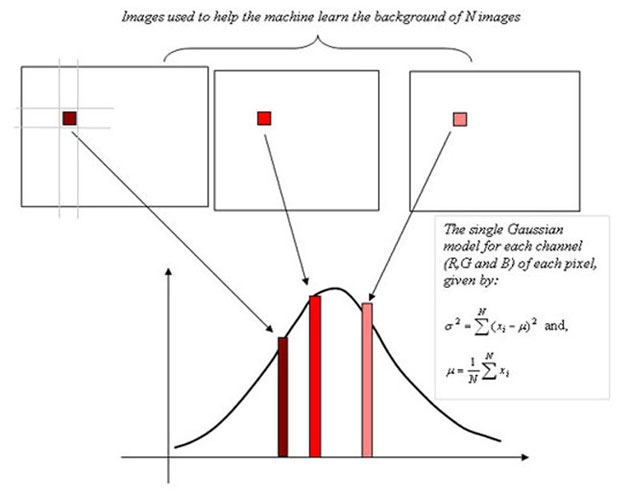
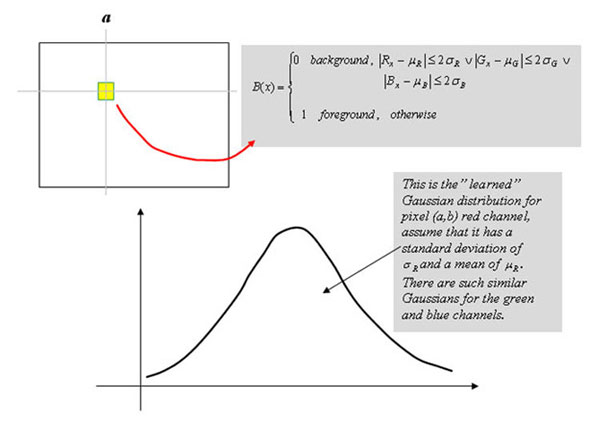
Today we had our third VIP research seminar. Dr. Chandrashekhara talked about how he's been going about trying to reduce the degree of freedoms/control points for his 3D model of the left ventricle. I am guessing that control points are points at which the model may be deformed. Later, Dr. Chandra told me that a control point has three degrees of freedom (i.e. 3D). He also talked about Subdivision surfaces. This concept is commonly used in computer graphics and animation. From what i understand, you try to smooth a mesh by continuous iterative refinements. The number of refinements are infinite. Here's an example.
There was also a few things said about B-splines. I was a bit embarassed to myself, for not knowing what a B-spline is. I first came across it in a computer graphics course in Toronto. Reviving myself of what it is, a spline is a special (usually complex) curve defined piecewise by polynomials. In computer graphics, splines are normally used in curve-fitting, i.e. to use a curve to approximate some complex shape. The most popular of all B-splines, is the cubic spline.
The talk by Dr. Chandra was followed by a PhD student. I couldn't quite figure out what she was saying. The paper she presented was pretty complicated, owing to the amount of heavy-duty equations it had. There was something about the EM-algorithm that the paper repeatedly referred to.
The seminar was followed by my meeting with Prof. Daniel. I quite completed what he had asked me to complete last week. I was asked to implement Cootes' statistical shape model using MATLAB. It was a trivial task, however, after looking at the approximations the model produced, there is a strong likelihood of a bug somewhere.
I also learned a few important things about modes, etc. If we train our model with n training samples (x1, .... , xn), we will have a covariance matrix which will have n eigenvectors. These n eigenvectors are our n modes. Using this "trained" model, we will now be able to produce an exact replica of an instance of our training set, xi, if we used all the n eigenvectors (i.e. modes). Note, that we use our original xi to produce an approximation for xi (xi hat). However, this is not the case (i.e. it is not an exact replica) if xi is not in the training set, for e.g. i > n. This is also not the case when we dont use all n eigenvectors (i.e. some modes). Actually, what Dr. Daniel told me later that this is a way of testing if our model is correct, i.e. if xi is in the training set, the xi produced should be identical to xi (provided all modes are used).
Hence, using all modes (all eigenvectors) explains 98% (~100%, 2% is noise) of the training set. It is interesting and worth investigating to see how this percentage varies with the number of modes. This week I will be trying to investigate the relationship between the number of modes and the percentage of data that can be explained. I will also try to see if this varies across different training set sizes.
The motivation here comes from the fact that if for smaller training set sizes, we can explain a large portion of our data using some number of modes (i am not sure how many modes), we would be able to reduce the task of manual annotation (landmarking), i.e. smaller training sizes require lesser annotations.
There was also a few things said about B-splines. I was a bit embarassed to myself, for not knowing what a B-spline is. I first came across it in a computer graphics course in Toronto. Reviving myself of what it is, a spline is a special (usually complex) curve defined piecewise by polynomials. In computer graphics, splines are normally used in curve-fitting, i.e. to use a curve to approximate some complex shape. The most popular of all B-splines, is the cubic spline.
The talk by Dr. Chandra was followed by a PhD student. I couldn't quite figure out what she was saying. The paper she presented was pretty complicated, owing to the amount of heavy-duty equations it had. There was something about the EM-algorithm that the paper repeatedly referred to.
The seminar was followed by my meeting with Prof. Daniel. I quite completed what he had asked me to complete last week. I was asked to implement Cootes' statistical shape model using MATLAB. It was a trivial task, however, after looking at the approximations the model produced, there is a strong likelihood of a bug somewhere.
I also learned a few important things about modes, etc. If we train our model with n training samples (x1, .... , xn), we will have a covariance matrix which will have n eigenvectors. These n eigenvectors are our n modes. Using this "trained" model, we will now be able to produce an exact replica of an instance of our training set, xi, if we used all the n eigenvectors (i.e. modes). Note, that we use our original xi to produce an approximation for xi (xi hat). However, this is not the case (i.e. it is not an exact replica) if xi is not in the training set, for e.g. i > n. This is also not the case when we dont use all n eigenvectors (i.e. some modes). Actually, what Dr. Daniel told me later that this is a way of testing if our model is correct, i.e. if xi is in the training set, the xi
Hence, using all modes (all eigenvectors) explains 98% (~100%, 2% is noise) of the training set. It is interesting and worth investigating to see how this percentage varies with the number of modes. This week I will be trying to investigate the relationship between the number of modes and the percentage of data that can be explained. I will also try to see if this varies across different training set sizes.
The motivation here comes from the fact that if for smaller training set sizes, we can explain a large portion of our data using some number of modes (i am not sure how many modes), we would be able to reduce the task of manual annotation (landmarking), i.e. smaller training sizes require lesser annotations.